|
III. Les Méthodes de correction de l’erreur systémique
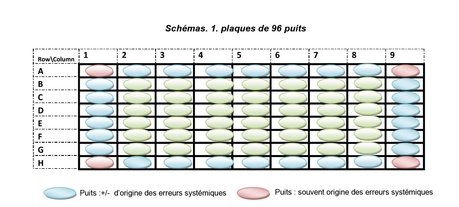
Souvent, les erreurs systématiques affect, les lignes, les colonnes et les périphéries des plaques, (Brideau el al., 2003), surtout les puits des quatre extrémités (voir Schémas.1). En effet, pour détecter et minimiser les effets des erreurs systématiques lors d'un criblage primaire plusieurs méthodes des corrections systémiques existent (Kevorkov et Makarenkov, 2006; Malo et al., 2006; Makarenkov et al., 2007 ; Tukey, 1977 ; Brideau et al., 2003, Malo et al., 2006). Dans ce rapport, et à l’aide de logiciel « HTS Corrector» développé par Dr. Vladimir Makarenkov et son équipe, je vais présenter et comparer des méthodes de correction : la soustraction de l’arrière-plan (Background Substraction), la soustraction de l’arrière plan approximatif (Approx. Background Substraction), la correction par puits (well correction), median polish, B score (Better Score). Pour ce faire, J’ai utilisé des données proposé par l'Université McMaster, et portant sur un criblage effectué au moyen de 1250 plaques pour inhiber l’enzyme « dihydrofolate reductase » d'un Escherichia coli. Ces données sont déjà disponibles sur le site de HTSCorrector «http://www.info2.uqam.ca/~makarenkov_v/HTS/home.php» |
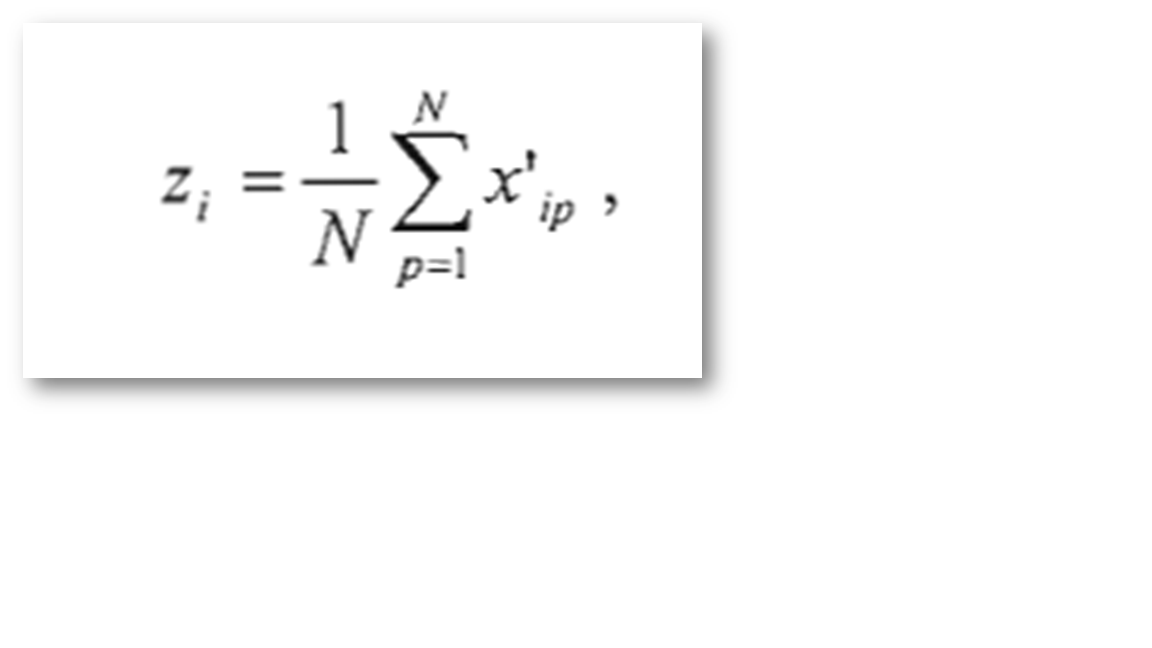
III.1. Correction par soustraction de l'arrière-plan «Background Substraction »Cette méthode se basait sur la mesure de l'arrière-plan d'un criblage HTS. Pour ce faire, deux approches sont utilisées : calcule la surface formée par la moyenne des «hits» trouvée pour chaque puits (avant correction) et une analyse des « hits » selon les lignes et les colonnes des plaques (Kevorkov et Makarenkov 2005a).
l'equation: X'ip est la valeur normalisée (décrite dans IV.2) du puits i du plaque p, Zi la valeur de l'arrière-plan du puits i et N le nombre total de plaques. |
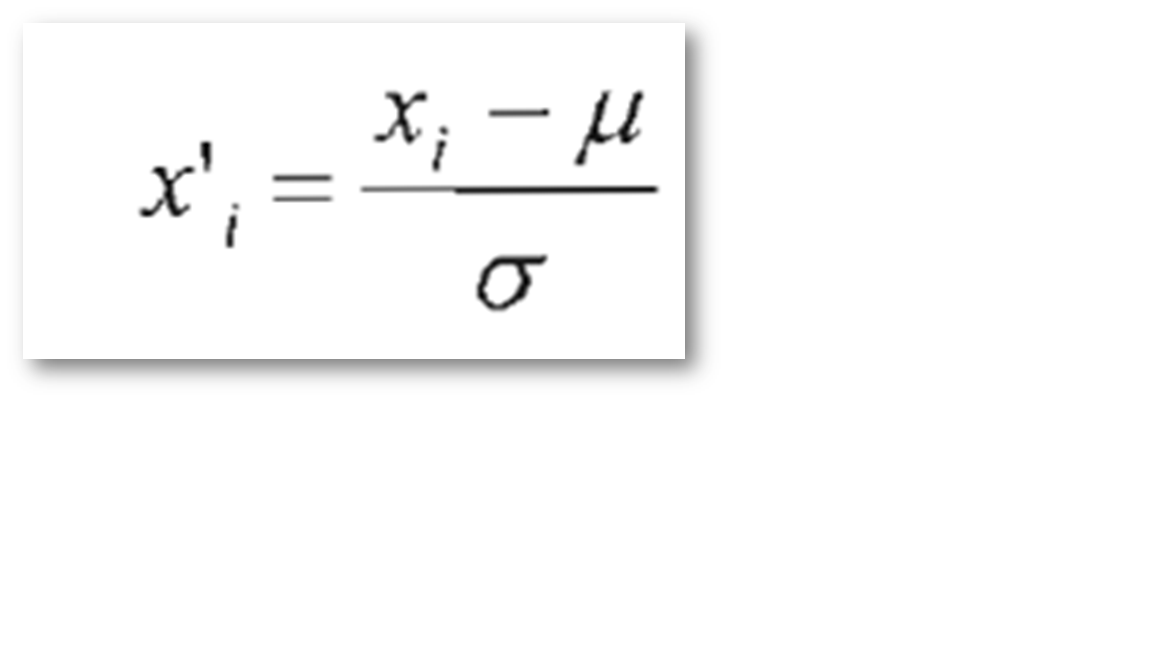
III.2 Correction par puits « Well correction »Pour pouvoir appliquer la nouvelle procédure de correction aux ensembles de données expérimentales, les hypothèses suivantes concernant les données HTS doivent être faites: les échantillons peuvent être divisés en actifs et inactifs; la majorité des échantillons criblés sont inactifs; les valeurs des échantillons actifs diffèrent significativement des valeurs inactives; les échantillons sont disposés de façon aléatoire dans les plaques; les données et les erreurs sont distribuées selon une loi normale ; les erreurs systématiques produisent une influence répétée dans les mesures de tous les puits des plaques. En outre, les puits, ne doivent pas contenir des échantillons appartenant à la même famille (Makarenkov et al. 2007).
Pour ce faire, Il faut avant tout, élimination des hits et des valeurs aberrantes si nécessaire. Cette élimination peut être effectuée pour réduire l'influence de ces derniers sur les moyennes (µ) et SD (écarts-types) des plaques. Il peut être particulièrement important lors de l'analyse des donnes avec peu des plaques « inférieures à 100 » (Makarenkov et al. 2007). Ensuite, normaliser les données brutes pour les rendre comparables et pouvoir ainsi procéder à leur analyse statistique. En effet, les données brutes peuvent présenter de légères différences selon les plaques et les conditions de manipulation (Kevorkov et Makarenkov 2005a, 2005b). La technique de normalisation proposée pour ce type de correction, normalisation centrée réduite «Z Score »voir équation ci-dessus. Une fois que les données sont normalisées à la plaque, il faut analyser (Correction et normalisation) les valeurs mesurées à l'intérieur de chaque puits et de chaque plaque. La méthode de correction de puits se compose de deux étapes principales: le nombre d'échantillons à travers les plaques (par exemple 1250 échantillons pour l'essai de McMaster), et les positions systématiques des puits. Enfin, cette méthode se termine par sélection des hits dans les données corrigées (Makarenkov et al. 2006). |
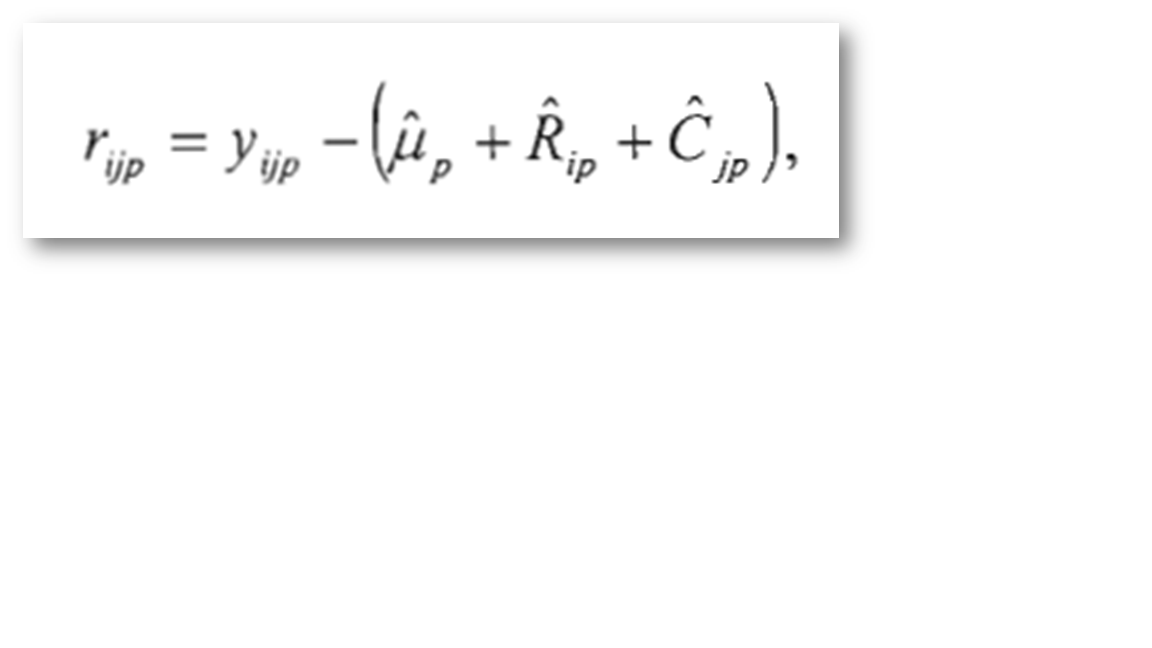
III.3 Correction polissage par médiane « median polish » La méthode «median polish » Développée par John Tukey en 1977, Pernet d'enlever les erreurs systématiques de lignes et de colonnes dans une matrice de valeurs. (Tukey, 1977). On calcule les erreurs, des valeurs mesurées par plaques selon la formule ci-dessus
|
